- Abstract
- Introduction
- Related Work
- HPO Based on RL
- Efficiency Improving Based on a Model
- Overall Framework
- Experiments
- Conclution
Abstract
- Hyper-Parameter Optimization(HPO)는 기계학습 성능향상을 위해 매우 중요한 작업이지만, 굉장히 비효율적이여서 어렵다.
-
본 논문은 강화학습을 이용해서 순차적으로 파라미터를 조정, 그리고 알고리즘 평가 모델을 학습시켜서 최적화 속도를 더 높였다. 이 평가모델은 부적확하기에 전체 horizon에서 적절히 사용하는 방법론을 도입하였다.
- CNN과 Gradient boosting 모델에 적용하여 101 task에 대해 실험하였더니, 86.1%의 task들에 대해 sota보다 더 높은 성능을 더 빠르게 도출하였다.
Introduction
- Manual Hyperparameter Tuning은 전문가의 경험과 노하우에 의존하며 많은 시간을 소요한다. 그래서 AutoML이 연구되고 있다.
- HPO는 hyperparameter와 성능은 비선형 관계를 가지고 있으며, search space가 굉장히 크고, 평가하는데 매우 시간이 오래걸리는 문제를 가지고 있다.
- 방법론으로는 크게 1. Basic search methods(grid/random search ), 2. Sample-based methods(Bayesian Optimization, evolutionary algorithm), 3.Gradient-based methods(직접적으로 partial derivative을 계산하여 다음 조합 수행) 가 있다.
- 이 논문에서는 HPO를 sequential decision process문제로 여기고 MDP로 모델링하여 LSTM기반의 RL로 문제해결. 그리고 학습 효율화를 위해 (오래걸리는 성능평가를) model based로 대체하여 reward를 계산하였다.
Related Work
- HPO 문제는 아래와 같이 정의할 수 있다.
-
- HPO를 풀기 위해서 다양한 최적화 알고리즘들이 있음
- Grid search, 경험적 최적화, Bayesian Optimization 그리고 최근엔 Population-based method까지…
- 강화학습은 MDP에서의 sequential decision making problem을 효과적으로 풀었음. Model-based로 효과적으로 AutoML에 적용된 사례도 있고 NAS에서도 쓰이는 방법론임.
HPO Based on RL
Sequential Decision Problem
- 일반적으로 복잡한 문제는 여러 쉬운 문제로 나누어서 처리하면 쉽다. Agent가 모든 hyperparameter를 한번에 Setting하는 것보다 하나씩 설정해나가는 방법이 더 효과적이다. 이렇게하면 자연적으로 문제가 sequential해진다.
- 여기서 Model-Based인 이유는 매 step마다 Dtrain 으로 ML모델을 학습후에 Dvalidation으로 평가한 값을 loss로 삼는다.
MDP formulation
-
n 개의 hyperparameter = n개의 horizon 상의서의 agent action
-
action A은 agent(Dt(λt) distribution) 출력
-
state S는 agent의 이전 action, st = Dt−1(λt−1)
-
reward R은 episode 마지막에서만 가지는 accuracy 값 \(r_t = 0\ for\ t ∈ [1, n)\ and\ r_n = accuracy\)
-
γ is a discount factor, and γ = 1.
Design of the Agent
- 이전 정보를 기억하기 위해 input embedding layer, output embedding layer, LSTM을 사용.
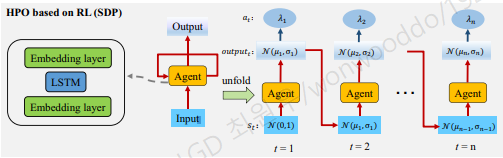
Overview of the HPO based on RL. The agent selects hyperparameters sequentially
-
lstm layer는 conditionality를 학습하게됨.
-
매 episode k 마다 순차적으로 n개의 hyperparameter를 선택함. (hyperparameter 순서는 random으로 하는데 성능에 영향이 없다 한다. section 6.7)
-
Agent는 distribution Dt에서 hyperparameter λt를 선택 (agent is Dt = N (µt, σt).)
Sampling from N (µ, σ)
- hyperparameter λ는 agent의 action인 N (µ, σ)으로부터 sampling함.
- tanh 함수(-1, 1) 범위에 따라 분포의 평균을 µ에서 µ ′ 로 조정하고 h값을 뽑은다음 해당 h에 맞게 rescaling 한다.
training the agent
- PPO를 이용해 Agent 학습
Efficiency Improving Based on a Model
Structure and Training of the Model
- 효과적으로 모델을 학습시키기 위해서 진짜 reward와 model로 부터 얻은 예측 reward를 번갈아 가면서 학습

- KL divergence를 통해 reward model 예측 사용을 control
Overall Framework
-
n개의 hyperparameter를 이전 선택에 기반하여 하나씩 선택.
-
ML모델이 선택된 hyperparameter로 Dtrain에 대해서 학습 수행
-
Dvalid으로 평가하여 reward feedback ; 효율성을 위해 진짜 reward와 예측한 reward를 번갈아가며 사용

Experiments
-
101 task에 대해서 XGBosst 와 CNN classifier에 대해서 실험
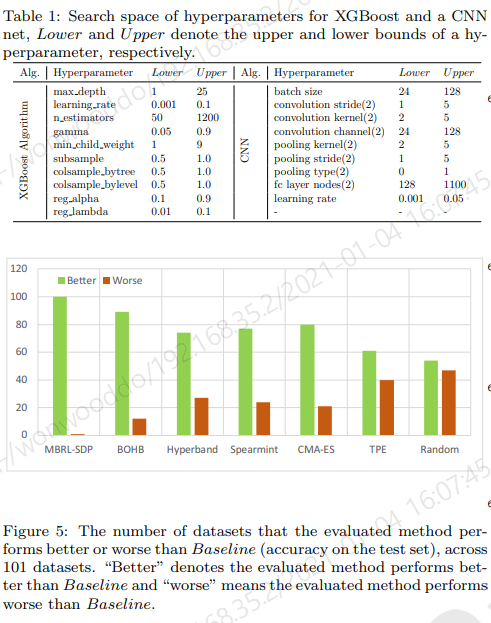
Experimental Details
-
- agent
- input embedding layer has 2 nodes, output embedding layer has 2 nodes
-
LSTM network consists of 3 layers - each 35 nodes
- learning rate : 0.007
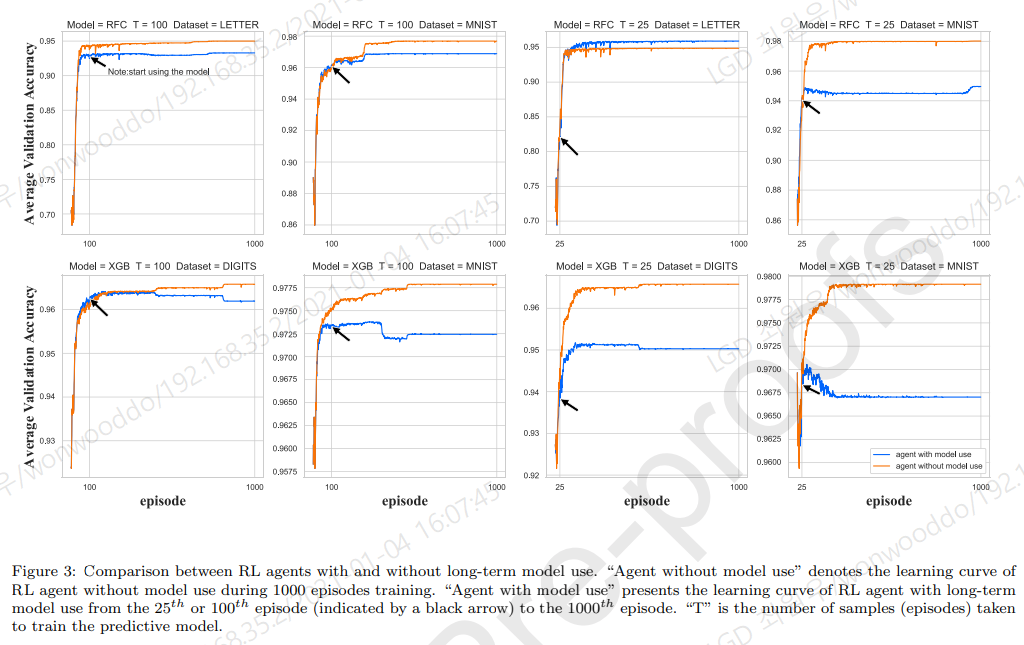
Study of Agent’s Structure
- Sequential 하게 hyperparameter를 선택해 나가는게 중요하다는것을 보이기 위해, 한 step에 hyperparameter를 선택하게끔 모델링하여 benchmark 비교하였다.
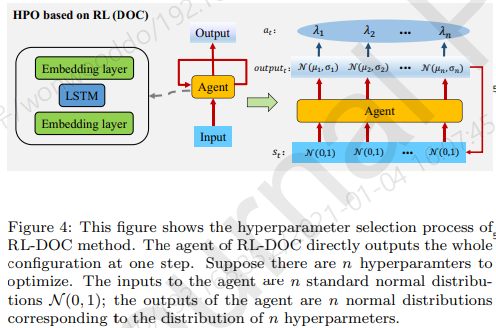
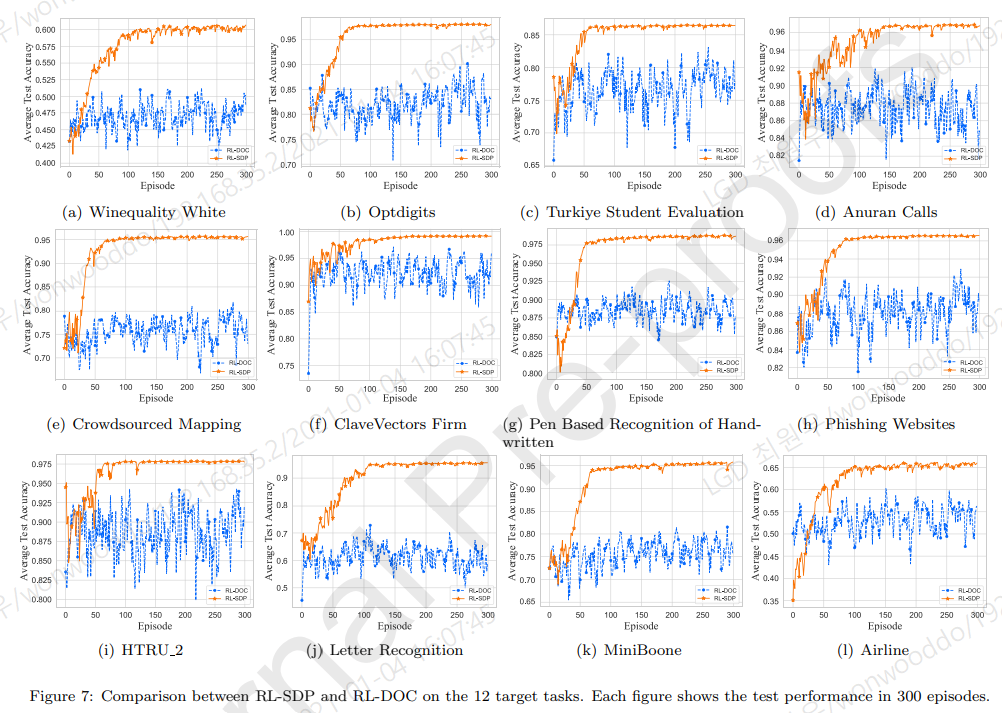
Effect of optimization order
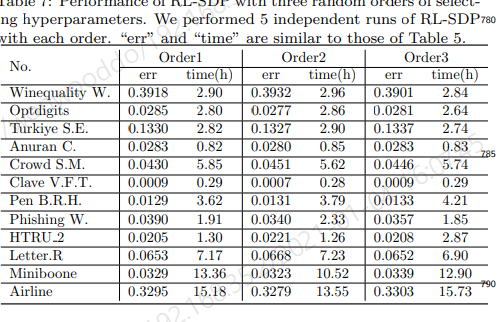
- hyperparameter 순서가 성능에 영향을 주는지 실험
- 순서는 상관없다. (이유는 논문에서 수학적으로 설명함)

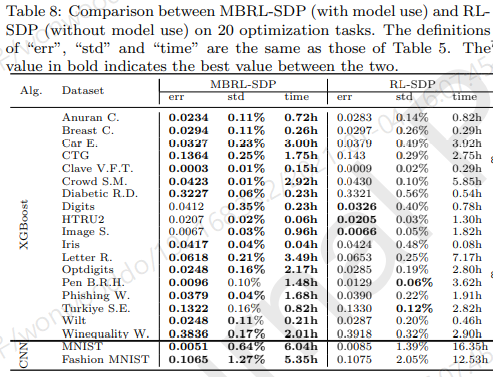
Effectiveness of the model
- 시간적으로 이득이 있음
Advantages of dynamical control of model

Conclution
- HPO 문제를 해결하기 위한 효율적인 model-based RL 방법을 제안
- HPO문제를 sequential decision problem으로 공식화 하고 MDP를 모델링.
- 강화학습으로 hyperparameter를 최적화
- 학습 효율화를 위해 선택된 hyperparameter의 ML 알고리즘을 평가하는 모델을 활용
- 모델의 부정확성으로 long-term model 사용은 결과를 악화시키기 때문에, 매개 변수 공간에서 모델 사용 전후의 정책 간 거리를 측정하여 모델 사용의 horizon을 dynamically control.